Скрипт за извличане на текст от изображения

Какво прави скрипта?
Скриптът използва библиотеката pytesseract за извличане на текст от изображения. pytesseract е OCR (оптичен разпознаване на символи) библиотека, която може да се използва за разпознаване на текст от изображения, сканирани документи и други носители.
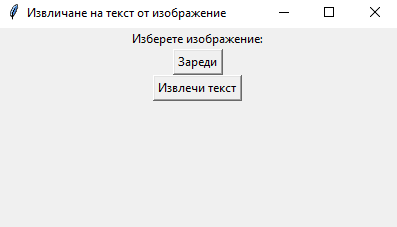
Скриптът създава графичен потребителски интерфейс (GUI), който позволява на потребителя да избере изображение, от което да се извлече текст. След като изображението бъде избрано, скриптът използва pytesseract, за да извлече текста от него. Текстът се показва в текстово поле в GUI.
Създаване на скрипт:
Създайте нов файл и добавете следния код:
import sys
import pyperclip # Оставете само този ред за import
import pytesseract
from PIL import Image
from tkinter import Tk, Label, Button, filedialog
# Задайте пътя към Tesseract изпълнимия файл
# Това е примерен път, трябва да го замените със своя реален път до Tesseract
pytesseract.pytesseract.tesseract_cmd = r'C:\Program Files\Tesseract-OCR\tesseract.exe'
class ИзвличателнаГУИ:
def __init__(self, майстор):
self.майстор = майстор
майстор.title("Извличане на текст от изображение")
self.етикет = Label(майстор, text="Изберете изображение:")
self.етикет.pack()
self.бутон_зареди = Button(майстор, text="Зареди", command=self.зареди_изображение)
self.бутон_зареди.pack()
self.бутон_извлечи = Button(майстор, text="Извлечи текст", command=self.извлечи_текст)
self.бутон_извлечи.pack()
self.етикет_текст = Label(майстор, text="")
self.етикет_текст.pack()
def зареди_изображение(self):
път_до_файл = filedialog.askopenfilename(filetypes=[("Файлове с изображения", "*.png;*.jpg;*.jpeg;*.gif")])
self.етикет.config(text="Избрано изображение: " + път_до_файл)
self.път_до_изображение = път_до_файл
def извлечи_текст(self):
try:
изображение = Image.open(self.път_до_изображение)
текст = pytesseract.image_to_string(изображение, lang='bul')
self.етикет_текст.config(text="Извлечен текст:\n" + текст)
pyperclip.copy(текст) # Оставете този ред за копиране на текста в клипборда
except Exception as e:
self.етикет_текст.config(text="Грешка: " + str(e))
if __name__ == "__main__":
корен = Tk()
корен.geometry("400x200")
приложение = ИзвличателнаГУИ(корен)
корен.mainloop()
Запазете файла и му дайте име, примерно extract_text_from_image.py
Използване на библиотеки:
- Pytesseract: Този модул служи за връзка с Tesseract OCR (Optical Character Recognition) и ни позволява лесно да извличаме текст от изображения.
- Pillow (PIL): Библиотеката за обработка на изображения, използвана за отваряне на изображения.
- Tkinter: Използвана за създаване на прост потребителски интерфейс.
- Pyperclip: Използва се за копиране на извлечения текст в клипборда.
Необходими стъпки преди стартиране на скрипта:
- Инсталирайте Python.
- Инсталирайте необходимите библиотеки:
pip install pytesseract Pillow pyperclip
3. Инсталирайте Tesseract OCR и настройте пътя към изпълнимия файл в скрипта.
Стартиране на скрипта:
- Запишете скрипта във файл с разширение
.py. - Отворете команден ред или терминал в директорията, където е записаният скрипт.
- Изпълнете командата
python име_на_скрипта.py
Скрипта автоматично копира извлечения текст в клипборда. Така можете да го поставите в други приложения, като например текстов редактор или електронна таблица.
Сега имате функционален скрипт, който ви позволява лесно да извличате текст от изображения, като добавяте удобство на крайния потребител чрез прост потребителски интерфейс.
Скриптът ще стартира GUI. Използвайте бутона "Зареди", за да изберете изображение, от което да се извлече текст. След като изображението бъде избрано, използвайте бутона "Извлечи", за да извлечете текста.
Благодарим ви за прочитането на статията! Ако намерихте информацията за полезна, можете да дарите посредством бутоните по-долу:
Donate ☕️ Дарете с PayPalDonate 💳 Дарете с Revolut